I have been testing using Ledger-Cli to track my expenses, so far I
have found the tagging system useful. In my ledger journal, each
transaction is associated with a project, for example, the below
transaction is assigned to project “2024 Monitor Stand”
This constraint I came up with helps avoid meaningless spending on new
shiny tools. Operationally, imposing this limitation on my book
provides flexible ways of querying the data.
For example, bring up the transactions that do not have projects
assigned to:
Table 2: Number of items purchased for each project
No. Items
Project
39
2024 Loft Lights
34
2024 Loft Insulation
32
2025 Garage Conversion
8
2024 Monitor Stand
2
General
The data shows the “2024 Loft Lights” project is by far the largest
. That was a simple project by itself, however, since that was my
first electrical project, I had to purchase a lot of stuff, 1.5mm
cables, clamps, grommets, connectors, switches, sockets etc.
Finally, I have the “refund” tag so I can flag up the items to remind
of myself to check if I received the refund fully.
My personal desktop is not booting (the motherboard is probably dead)
so I have been setting my server so I can work while sorting things
out.
I got stuck in getting magit working in emacsclient: I thought I could
run ssh-add inside of Emacs that would allow magic to access my
git repos using ssh, but apparently, it is not the case.
After some digging, I learnt that the problem I have to solve is to
run one ssh-agent in the background and then make the Emacs/Magit or
any programs hook onto it. Then once I run ssh-add and type the
passphrase for the first time, either inside of Emacs or in a bash
terminal, everything would work.
Implementation
Drop the following unit file below to
~/.config/systemd/user/ssh-agent.service.
The environment variable SSH_AUTH_SOCK is specified. It can be
anywhere as long as this environment variable in other programs
points to the same location.
ssh-agent is invoked with the -a option to provide an address
specified in the above step.
The $t is a specifier1 in systemd, it is equivalent to
$XDG_RUNTIME_DIR variable in Debian. It points to the runtime
temporary directory which apparently is safer2 than the /tmp
directory. The runtime directory was cleaned up after stopping the
ssh-agent so it is non-persistent.
There are programs developed to solve this specific problem (see Debian wiki). While using such a program seems like a simpler
alternative (e.g. keychain), I prefer to use systemd as the unified
approach for managing background services. I have been using it for
emacsclient, and I’m adding ssh-agent to it.
What is your preference? How do you solve this problem?
The little Raspberry Pi 4 (RP4) served me well in the last two
years. I used it to host NextCloud/Syncthing for syncing files between
devices, scraping financial data from Yahoo Finance and TimeMachine
for MacOS backup.
The latest addition to the service stack is paperless-ngx. It allows
my Canon printer/scanner to send digital copies of documents directly
to the RP4 or Gmail.
The RP4 handles all the demands without showing any signs of struggle.
It costs as little as 6kW per hour while the Xbox One S draws 11kW
while sleeping. Thanks to the energy crisis in the UK, I started to
appreciate the energy efficiency of RP4. The ARM chips in it really
impressed me.
Lack of NAS Capacity
A 3TB portal hard drive (WD My Passport) was attached to the PR4 to
store media data. The USB 3.0 connector is surprisingly stable and
fast. With both ends connected by ethernet cables, the file transfer
speed can reach up to 100 MB/s. When my MacBook Pro uses Wi-Fi, the
speed drops to about 40-50 MB/s but it is still great because of the
convenience.
Later I started using it as a NAS to store the Final Cut Pro
library. The 4k home gym videos I shot using iPhone 12 Pro are
numerous 1! The hard drive keeps getting filled up.
I can get another portal hard drive, but then it will get filled up
again, say in less than a month? So it occurred to me that I need a
proper home server with full NAS capacity.
Looking for a Successor
I did a bit of research but I am not able to find a good product. I
suspect the reason is the NAS build is a niche area while the PC
industry is gaming-centric, focusing on getting faster, bigger, and
fancier hardware with unnecessary RGB lights, that is where the
profits are I presume.
I came across some innovative products on AliExpress from China, such
as the TopTon N5105 board. It is more powerful, consumes
slightly more electricity, and it has 6 SATA cables! It would be a
perfect successor for my PR4.
But I am not comfortable ordering electronic stuff from
AliExpress, returning it or sending it back for repair would be a nightmare.
PS: The company is growing fast, it continued to innovate, and the product
lines extended to Intel N100 with an additional NVME drive and a USB-C. Their website
and marketing materials look notched up quite a bit. I kind of regret not
taking the risk back then.
Unexpected
The other day, I was re-organising (again) my home office, so had to
move a bookshelf. I started moving it without taking everything off,
then a motherboard fell off. It was the z170a with an i5-6600k and a
heat sink attached to it. The motherboard was in my first desktop that
I purchased 10 years ago when I started participating in Kaggle competitions
in 2014.
After a quick inspection, I saw some pins were bent. I felt ashamed and
sorry for the motherboard that I had not taken care of it. So I made a
promise: if it survived the fall, I would use it for my NAS.
Well, it did so I found my NAS.
Setting up z170a
While putting it up, one SATA port was snapped and came up, but the
rest is still fine. Apart from that, everything else went smoothly. The
Debian 12 became much easier to install with the isohybrid technology
and the non-free firmware is now part of the installation image
itself.
The server setup scripts and configuration are saved in a
selfhosted-services git repository so restoring the services took
little efforts.
I had one little trick: I assigned the IP address of RP4 to the new
z170a server so that on the client side I didn’t have to change
anything. This was achieved rather easily: few clicks in the ASUS
router web UI and then a reboot.
While setting it up, I noticed the z170a system is much more
responsive, thanks to the 3.5 GHz i5-6600k CPU and a much faster SSD
over the SD card. I was able to run multiple processes at the same
time.
The longest part is copying files from the 3TB portal hard drive to the
z170a’s internal HDD, which took about 20 hours.
It has great extensibilities: there are 3 free SATA for HHD and two
PCIe slots.
Power Consumption
The only downside is that it consumes a lot more electricity. When testing
in barebone, it drew only 10W. After putting everything together with
additional HDDs, fans, and ethernet cable, the power metre jumped to
45W. I removed hard drives one by one to see where the bottleneck is.
No HDD, 27W
IronWolf alone, 32W, 5W increases.
IronWolf + Seagate, 37W, another 5W increase.
IronWolf + Seagate + Toshiba, 45W, 8W increase.
So I kept only IronWolf which is a 3TB NAS grade HDD.
I also tried tweaking the BIOS and Linux kernel to get to C-states but
I felt it was over-engineering so I am happily settled down with 27W.
Footnotes
1 I record weightlifting to correct and improve my
techniques.
I used ledger-cli1 before and it was a painful experience. The
problem was not rooted in the tool but in how I intended to use it: I
wanted to track all my expenses, from buying a cup of coffee to
booking a holiday package. When I started this journey, there was a
massive jump from knowing little to nothing about personal finance to
doing double-entry accounting in plain text.
Though I gave up, it introduced me to the idea of owning my bank
transaction data in text files on my personal computer. So over the
years, I manually curated about 8 years of historical transaction
data.
If you haven’t done so, I strongly recommend you go to your banks’
website and download the transaction data manually, going as far back as
you can. You will notice that the banks only give access to 3-5 years
of data2. It’s a shame that banks use outdated technologies but
it is better than having nothing.
Since I had the data, I did some analysis and charts in Python/R. But
I kept wondering what ledger-cli can offer. I occasionally saw blog
posts on ledger-cli in the Emacs communities, so there must be
something out there.
It also has become a personal challenge. I turned not to give up but
put it aside to tackle it again after I got older.
Baby Steps
Hopefully, I had become smarter as well. This time, to ensure I can
successfully adopt the tool, I am going to reduce the scope to limit
to only tracking DIY project expenses.
I love DIY and I wish I had more days for DIY projects. It is usually
labour-intensive and I feel hyped and extremely confident after a couple
of DIY. Pairing it with learning ledger-cli, a cognitive-intensive
activity, would make them a nice bundle3.
Though the usage is simple, the question it can answer is important. I
want to know, during or after the DIY project, how much it exactly
costs. I could use a much simpler tool, like spreadsheets or a
pen/notebook, but I want it to be a stepping stone to acquire
ledger-cli properly in the future.
Why? - Effort Estimation
I need an accurate answer to the actual costs so that I can use the
data to train myself in cost estimation. This is an very important
skill to have as a homeowner, it would put me in a much better
position in negotiation with the tradesman. A lot of the people
in the UK complained that they or their relatives got ripped off by
tradesman.4
In general, house repairs and improvements are getting much more
expensive every year, due to the shortage of labourers, inflation and
Brexit etc. To give an example using my last two quotes, adding an
electrical socket costs £240 and replacing a small section of water
pipes costs £500.
I have a good habit of using org-mode to track time, my goal to add
ledger-cil to my system to track the expenses. After that, I would
know if it is really worth doing the DIY or finding a proper
tradesman. The total cost itself is not the only metric that matters,
but n very essential one to have.
From a modelling perspective, it is not a big problem to have highly
correlated features in the dataset. We have regularised Lasso/Ridge
regression that are designed to deal with this kind of dataset. The
ensemble trees are robust enough to be almost immune from this. Of
course all model requires proper hyperparameter tuning with proper
cross validation.
The problem raises in understanding the feature contributions: if
there are 5 features that are highly correlated, and their individual
contribute could be tiny, but their true contribution should be
aggregated by adding the contribution together and considered them as
a group, e.g. adding their coefficients in Ridge, and adding feature
importance in LightGBM.
If their aggregated feature importance turns out to be indeed little,
I can remove them from the model to have a simpler model. A mistake I
used to make is removing the correlated features based on their
individual feature importance, it leads to less performant models.
A better and cleaner approach is to the clean up correlated features
to begin with, then I won’t need to do the feature importance
aggregation, and it would speed up the model development cycle: there
are less features to look at, to train the model, to verify the data
qualities etc. When the model goes live in production, it translates
to less data to source and maintenance.
Implementation
So I need to enrich my tool set to identify highly correlated
features. I couldn’t find an existing library that does that, so I
implemented it myself.
The key steps are:
Based on the correlation matrix, create a correlation long
table. Each row stands for the correlation between feature $X_1$
and feature $X_2$. Assuming there are three features in the
dataset, the table looks like this.
Row
X1
X2
Corr
1
A
B
0.99
2
A
C
0.80
3
B
C
0.95
Remove rows if the correlation is less than the threshold $T$. It
significantly reduces the input to Step 3.
If the threshold is 0.9, then the Row 2 will be removed.
Treat the correlation table as a directed graph,
Let $E$ be the unexplored nodes, filled with all the features
$X_1$ in the start, $R$ is the result.
For each node in $E$,
Continue to travel the graph in depth-first fashion until
there is no connections left, and add the connected node to
the result $R$ at each visit.
Remove the connected nodes in $R$ from the remaining nodes to
explore in $E$.
The vanilla Python code corresponding to Step 3 is listed below. The
ds object is a pandas.DataFrame, multi-indexed by $X_1$ and $X_2$,
so ds.loc['A'].index gives all the connected features from $A$ whose
correlation with $A$ is large than the provided threshold.
deffind_neighbors(ds:pd.DataFrame,root:str,res:set):"""recursively find the nodes connected with root in graph ds.
"""res.add(root)ifrootinds.index:ns=ds.loc[root].index.tolist()forninns:find_neiboughr(ds,n,res)else:return[]deffind_correlated_groups(ds:pd.DataFrame):"""
The ds object is a pandas.DataFrame, multi-indexed by X1 and X2.
"""res=defaultdict(set)# contiune til all nodes are visited.
cols=ds.index.get_level_values(0).unique().tolist()whilelen(cols)!=0:# always start from the root as ds is directed graph.
col=cols[0]find_neighbors(ds,col,res[col])# remove connected nodes from the remaining.
forxinres[col]:ifxincols:cols.remove(x)returnres
The result is a collection of mutually exclusive groups. Each group
contains a set of highly correlated features, for example
Group A: {A, B, C}
Group D: {D, K, Z}
The next step is to decide which feature to keep and remove the rest
within each group. The deciding factors can be data availability
(e.g. choose the one feature with less missingness), costs in data
sourcing (e.g. free to download from the internet) or familiarity
(e.g. the feature is well understood by people) etc.
Parameterisation
There are two hyperparameters:
The correlation type: It can be Pearson for numerical data and Spearman
for ordinal/categorical data. For a large dataset, it would take
some time to calculate the correlation matrix.
The correlation threshold $T$: The higher the threshold, the less
number of features to remove, so it is less effective. However, if
the threshold is set too low, it leads to a high false positive
rate, e.g. two features can be correlated, but they can still
complement each other in the model.
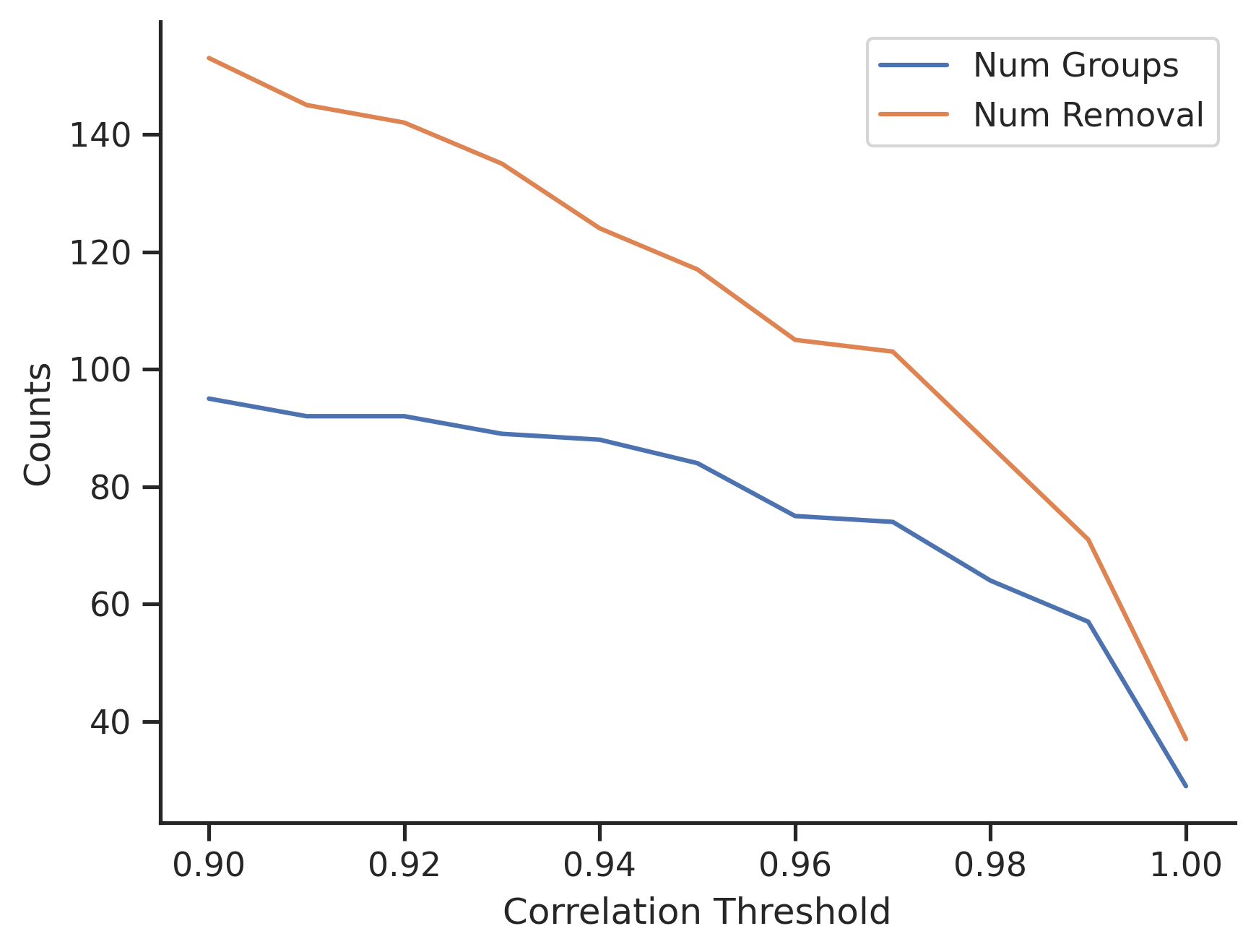
I would test a range of values from 0.9 to 1, and review the
results. Below graph shows the number of features to remove
with varying thresholds.
When $T=0.9$, there are about 95 groups, and in total 153 features to remove.
When $T=1$, there are 29 groups, and in total 37 features to
remove.
Proper end-to-end test runs are required to identify the best
hyperparameters. As a quick rule of thumb, those 37 duplicated
features identified with $T=1$ can be dropped without further testing.
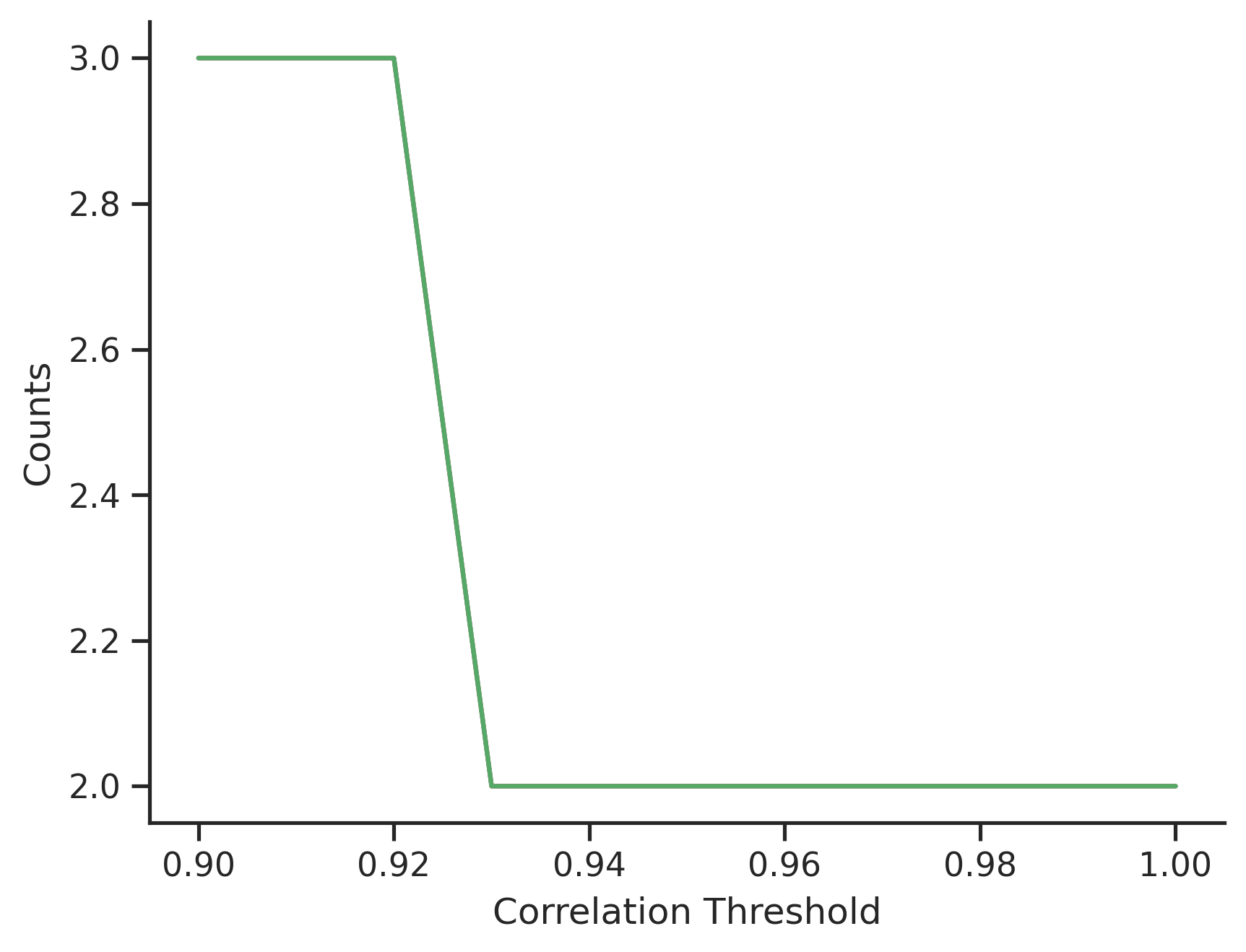
The group sizes with varying thresholds $T$ provide an interesting
insight of the data. The 75% percentile of the group sizes is plotted,
which suggests that apart from the 33 duplicated features, there are a
large number of paired features (i.e. group size is 2) whose
correlation is large, more than 92%.