How Much Does Threadripper 3970x Help in Training LightGBM Models?
13 Dec 2023Table of Contents
- Experiment Set up
- i5-13600k - Efficient Cores Count
- 3970x - Disappointing Results
- i5 vs. 3970x - Training in Parallel
- CPU vs. GPU - Impressive Performance
- Is the 3970x worth it?
Back in my Kaggle days, I always wondered how much my ranking could improve with a better computer. I finally pulled the triggers (twice) and got myself a 32-Cores Threadripper 3970x workstation.
Before I can tell if it helps my Kaggle competitions or not, I thought it would be interesting to quantify how much benefits I can get from upgrading the i5-13600k to 3970x in training LightGBM model.
The TLDR is:
- The speedup is 3 times in training LightGBM using CPU.
- To my surprise, it is 2 times faster using GTX 1080Ti GPU than i5-13600k.
- There are no obvious gains from GTX 1080Ti to RTX 3080.
Experiment Set up
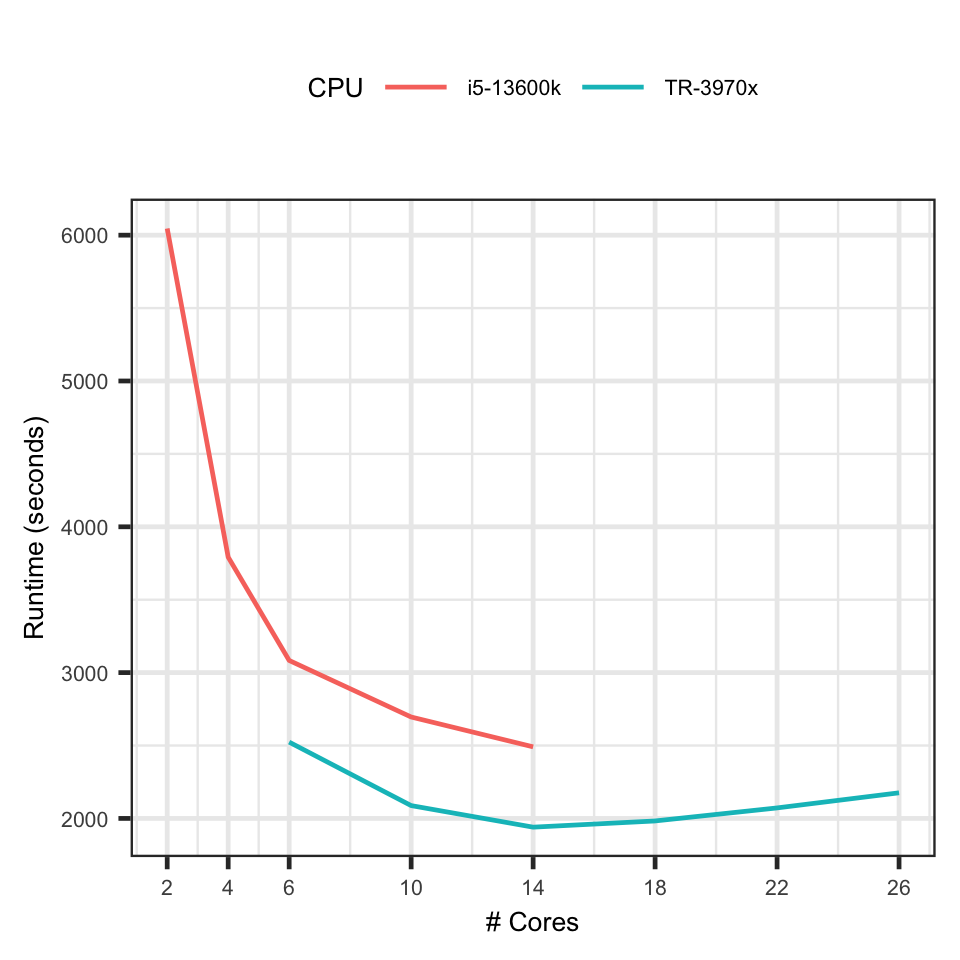
I use the data in the Optiver - Trading At The Close competition. There are about 500,000 rows and 100 features. I train a 3-fold (expanding window) LightGBM model. Repeating the same process with varying numbers of cores used in the process to get a performance graph like this:
Threadripper 3970x vs i5-13600k: Train LightGBM Models on CPU
i5-13600k - Efficient Cores Count
The i5-13600k has 6 performance cores and 8 efficient cores. In practice, I never use more than 6 cores in training ML models. My theory is mixing fast performance and slow efficient cores leads to a worse performance than using the performance cores alone. By specifying 6 cores, I assume the OS uses only performance cores.
The result shows that I was wrong - Using more than 6 cores can give considerable performance gain. It reduces the runtime by 10 minutes from 6 to 14 cores.
The only plausible explanation is that when training LightGBM with 6 cores, it is already mixed with efficient cores. Therefore I see an increases in performance while adding more cores.
Regardless I will start to use 12 cores in practise.
3970x - Disappointing Results
I know the performance gain will not scale linearly with the number of cores but I wasn’t expecting that adding more cores can slow down the model training.
The graph shows the 3970x achieves its best performance at using 12 cores. After that, adding more cores increases the runtime.
This type of behaviour is usually observed in simple tasks where the overhead of coordinating between cores outweighs the benefits of extra cores bring in.
But training thousands of decision trees with half a million data points is definitive not in this simple task category. So I don’t understand why this is happening.
i5 vs. 3970x - Training in Parallel
For 6 cores, it took i5 51 minutes and 3970x 42 minutes, which is about 1.2 speedup which is not bad. The same speed boost is also observed at using 10 and 12 cores.
I found this consistent speedup confusing because there’s a mix of performance and efficient cores in i5, so in theory every performance core I add in 3970x should increase the performance marginal when compared to i5.
In general, because of the poor scalability with respect to the number of cores, the best performance is achieved when training the model with a small number of cores and running multiple training in parallel. This is the trick I use to get the extra performance boost for CPU-bound tasks.
Here’s the setup for each computer:
- i5-13600: use 6 cores to train each model, and train 2 models in parallel. They are 2 cores left for OS background activities.
- 3970x: also use 6 cores to train each model, but train 5 models in parallel! It also leaves 2 cores for OS background activities.
After a little bit of maths, it takes 14 hours for 3970x to train 100 models, and 42.8 hours for i5, so the speedup is 3 times. This is just based on my theory. It would be good to actually run the experiment and see the actual numbers.
| CPU | Runtime of 1 model (S) | No. models in Parallel | No. Batches | Total Runtime (H) |
|---|---|---|---|---|
| 13600k | 3083 | 2 | 50 | 42.8 |
| 3970x | 2523 | 5 | 20 | 14.0 |
So the most benefit I can get from 3970x is in running multiple experiments in parallel!
CPU vs. GPU - Impressive Performance
I have a GTX 1080Ti in my i5 PC for running deep learning models and CUDA code. I never use it for LightGBM because the GPU implementation was slower than the CPU in 2019 when I tried it.
In summer Guolin Ke, the author LightGBM, promised a significant improvement in GPU performance when he was looking for volunteers to work on improving LightGBM’s GPU algorithm.
Since I have the experiments set up already, it took me little time to repeat the same experiments using the GPU trainer. All I did was adding device_type=’gpu’ in the configuration files.
| # CPU Cores | i5-13600k | tr-3970x | GTX 1080ti | RTX 3080 |
|---|---|---|---|---|
| 6 | 3083 | 2523 | 1435 | 1256 |
| 10 | 2695 | 1940 | 1269 | 1147 |
The result shocks me: I can get 2 times speedup just by switching from i5 to 1080Ti with one additional line in the config and it outperforms the 3970x in training single model setting by a big margin!
Is the 3970x worth it?
I found myself asking this question after seeing the results. In the context of this experiment, no, it makes no sense to spend £2,000 to get 3 times speedup when I can simply switch to 1080Ti to get 2 times speed up with no costs.
However, the reason I go for the Threadripper and the TRX40 platform is the 128 PCIe 4.0 lanes. The workstation is capable of running 4 GPUs at the same time at full capability while as i5 can only run 1 GPU.
If I had 4 GTX 3080 installed, it would finish training 100 models in just under 8 hours! That’s 5.25 speedup to i5 and 1.75 speedup to 3970x in parallel setting.
This calculation is not for just entertainment. It turns out that utilising multiple GPU to train gradient boost tree can be a really big thing!
I just found another reason to buy more GPUs! :)