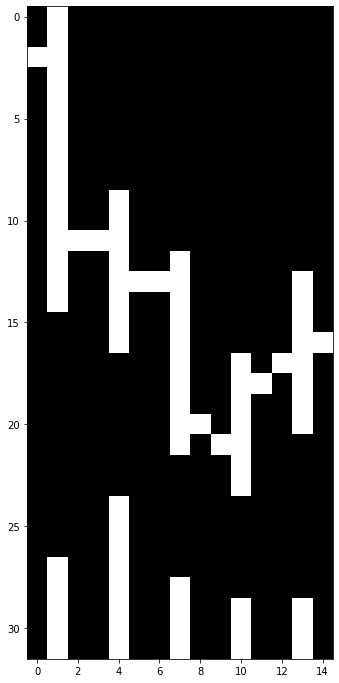Back in my Kaggle days, I always wondered how much my ranking could
improve with a better computer. I finally pulled the triggers (twice)
and got myself a 32-Cores Threadripper 3970x workstation.
Before I can tell if it helps my Kaggle competitions or not, I thought
it would be interesting to quantify how much benefits I can get from
upgrading the i5-13600k to 3970x in training LightGBM model.
The TLDR is:
The speedup is 3 times in training LightGBM using CPU.
To my surprise, it is 2 times faster using GTX 1080Ti GPU than
i5-13600k.
There are no obvious gains from GTX 1080Ti to RTX 3080.
Experiment Set up
I use the data in the Optiver - Trading At The Close
competition. There are about 500,000 rows and 100 features. I train a
3-fold (expanding window) LightGBM model. Repeating the same process
with varying numbers of cores used in the process to get a performance
graph like this:
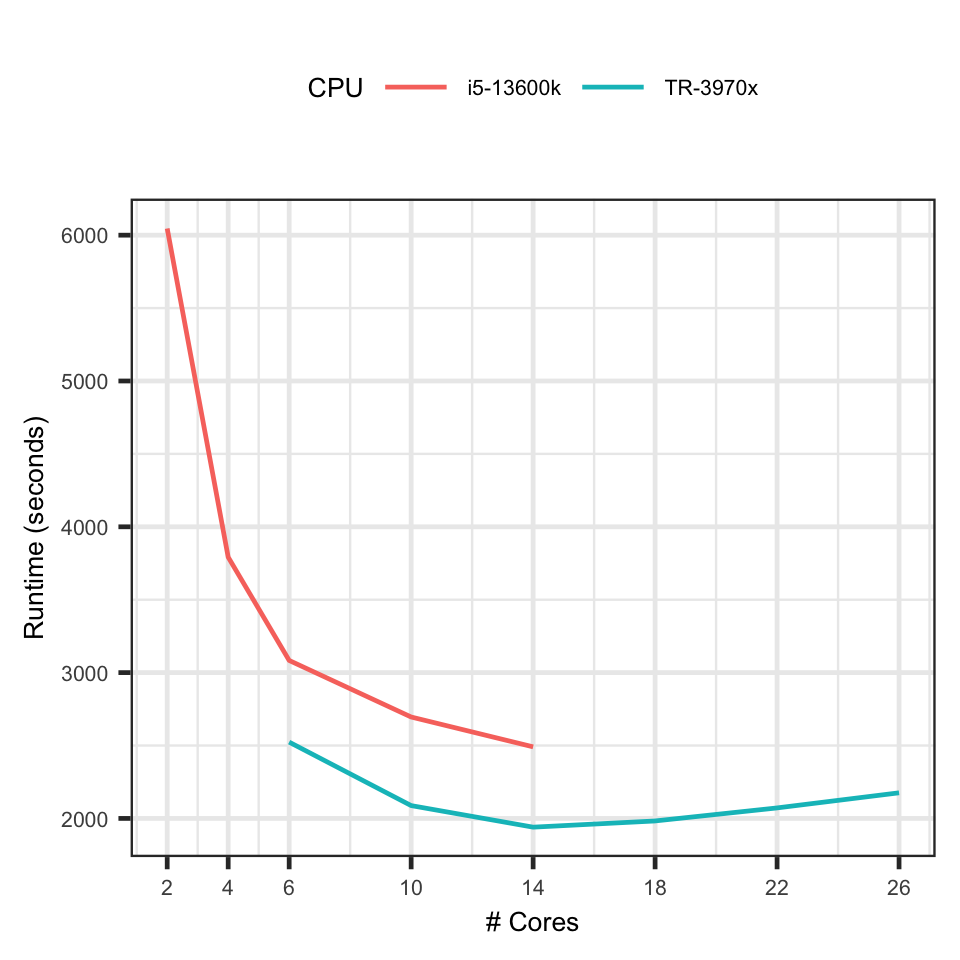
Threadripper 3970x vs i5-13600k: Train LightGBM Models on CPU
i5-13600k - Efficient Cores Count
The i5-13600k has 6 performance cores and 8 efficient cores. In
practice, I never use more than 6 cores in training ML models. My
theory is mixing fast performance and slow efficient cores leads to a
worse performance than using the performance cores alone. By
specifying 6 cores, I assume the OS uses only performance cores.
The result shows that I was wrong - Using more than 6 cores can give
considerable performance gain. It reduces the runtime by 10 minutes
from 6 to 14 cores.
The only plausible explanation is that when training LightGBM with 6
cores, it is already mixed with efficient cores. Therefore I see an
increases in performance while adding more cores.
Regardless I will start to use 12 cores in practise.
3970x - Disappointing Results
I know the performance gain will not scale linearly with the number of
cores but I wasn’t expecting that adding more cores can slow down the
model training.
The graph shows the 3970x achieves its best performance at using 12
cores. After that, adding more cores increases the runtime.
This type of behaviour is usually observed in simple tasks where the
overhead of coordinating between cores outweighs the benefits of extra
cores bring in.
But training thousands of decision trees with half a million data
points is definitive not in this simple task category. So I don’t
understand why this is happening.
i5 vs. 3970x - Training in Parallel
For 6 cores, it took i5 51 minutes and 3970x 42 minutes, which is about
1.2 speedup which is not bad. The same speed boost is also observed at
using 10 and 12 cores.
I found this consistent speedup confusing because there’s a mix of
performance and efficient cores in i5, so in theory every performance
core I add in 3970x should increase the performance marginal when
compared to i5.
In general, because of the poor scalability with respect to the number
of cores, the best performance is achieved when training the model with
a small number of cores and running multiple training in parallel. This is
the trick I use to get the extra performance boost for CPU-bound
tasks.
Here’s the setup for each computer:
i5-13600: use 6 cores to train each model, and train 2 models in
parallel. They are 2 cores left for OS background activities.
3970x: also use 6 cores to train each model, but train 5 models in
parallel! It also leaves 2 cores for OS background activities.
After a little bit of maths, it takes 14 hours for 3970x to train 100
models, and 42.8 hours for i5, so the speedup is 3 times. This is just
based on my theory. It would be good to actually run the experiment
and see the actual numbers.
Table 1: Training 100 models in parallel setting.
CPU
Runtime of 1 model (S)
No. models in Parallel
No. Batches
Total Runtime (H)
13600k
3083
2
50
42.8
3970x
2523
5
20
14.0
So the most benefit I can get from 3970x is in running multiple
experiments in parallel!
CPU vs. GPU - Impressive Performance
I have a GTX 1080Ti in my i5 PC for running deep learning models and
CUDA code. I never use it for LightGBM because the GPU implementation
was slower than the CPU in 2019 when I tried it.
In summer Guolin Ke, the author LightGBM, promised a significant
improvement in GPU performance when he was looking for volunteers to
work on improving LightGBM’s GPU algorithm.
Since I have the experiments set up already, it took me little time to
repeat the same experiments using the GPU trainer. All I did was adding
device_type=’gpu’ in the configuration files.
Table 2: Runtime of training a single mdoel
# CPU Cores
i5-13600k
tr-3970x
GTX 1080ti
RTX 3080
6
3083
2523
1435
1256
10
2695
1940
1269
1147
The result shocks me: I can get 2 times speedup just by switching from
i5 to 1080Ti with one additional line in the config and it outperforms
the 3970x in training single model setting by a big margin!
Is the 3970x worth it?
I found myself asking this question after seeing the results. In the
context of this experiment, no, it makes no sense to spend £2,000 to
get 3 times speedup when I can simply switch to 1080Ti to get 2 times
speed up with no costs.
However, the reason I go for the Threadripper and the TRX40 platform
is the 128 PCIe 4.0 lanes. The workstation is capable of running 4
GPUs at the same time at full capability while as i5 can only run 1
GPU.
If I had 4 GTX 3080 installed, it would finish training 100 models in
just under 8 hours! That’s 5.25 speedup to i5 and 1.75 speedup to
3970x in parallel setting.
This calculation is not for just entertainment. It turns out that
utilising multiple GPU to train gradient boost tree can be a really
big thing!
This static blog is built using Jekyll in 2014. It survived after 7
years which is a success when it comes to personal blogging. Part of
the reason is having a good blogging workflow: write posts in Org
Mode, export to HTML with a front matter, build the site using Jekyll,
send the folder to an Amazon S3 bucket, and that’s it. All done in
Emacs of course.
Technical Debt
I added a few things to the workflow to enhance the reading experience
including code highlights, centred images with caption, table of
content etc. There are more features I want to add but at the same
time, I want to be able to just write.
With that mindset, whenever there are issues, I apply quick fixes
without a deep understanding of the actual causes. It seems efficient
until recently some fixes become counter-productive.
I started seeing underscore (_) is exported as \_ and <p> tag
appears in code snippets. It all sounds like quick fix, but I just
couldn’t get it correct after few hours. For the last few posts, I had
to manually fix them for each of the read-edit-export-fix iteration.
Revisit the Tech Stack
I have an ambitious goal for this blog. So it is time to go sweep the
carpet. I studied the technologies used for this blog, Jekyll, AWS and
Org Mode exporting. It was a good chance to practise Org-roam for
taking atomic notes. The time is well spent as I learnt a lot.
I was impressed I got the whole thing up and running 7 years ago. I
don’t think I have the willpower to do it now.
Still, there are a lot of things that I do not have a good understand,
e.g. the Liquid templates, HTML and CSS tags etc. The syntax just
puts me off.
Long Ride with Jekyll
I prefer a simple format like Org Mode or Markdown and don’t have to
deal with HTML/CSS at all. There are a couple of occasions when I
cannot resist the temptation to look for an alternative to
Jekyll. There’s no luck in the search. It seems HTML is the only way
because it is native to the web.
So the plan is to stick with Jekyll for at least a few years. In the
next couple of weeks, I’d try to fix all the issues, after that,
gradually add more features to enhance the writing and reading
experience.
I hope people who also uses the similar tech stack (Org-mode, Emacs,
Jekyll, AWS) can benefit my work.
I switched to MacOS last year for editing home gym videos. I was and
am still amazed by how fast the M1 chip is for exporting 4K
videos. The MacOS also enriched the Emacs experience which makes it
deserve another blog post.
So I have been slowly adapting my Emacs configuration and workflow to
MacOS. One of the changes is the Emacs server.
The goal is to have fully loaded Emacs instances running all the time
so I can use them at any time and anywhere, in Terminal or Spotlight. They are
initiated upon login. In cases of Emacs crashes (it is rare but more
often than I like) or I have to stop them because I messed up the
configuration, they restart automatically.
It is an extension of Emacs Plus’ plist file. I made a few changes for
running two Emacs servers: one for work (data sciences, research) and
one for personal usage (GTD, books). Taking the “work” server as an
example, the important attributes of the plist configuration file are:
Line 5: The unique service name to launchctl
Line 8: The full path to the Emacs program. In my case, it is
/opt/homebrew/opt/emacs-plus@31/bin/emacs
Line 9: The “–fg-daemon” option set the Emacs server name to
“work”. Later I can connect to this server by specifying “-s=work”
option to emacsclient
Line 13: The KeepAlive is set to true so it keeps trying to
restart the server in case of failures
Line 16 and 18: The location of standard output and error
files. They are used to debug. Occasionally I have to check those
files to see why Emacs servers stopped working, usually because of
me introducing bugs in my .emacs.d.
With the updated plist files in place, I start the Emacs servers with
The launchctl list | grep -i emacs is a handy snippet that lists the
status of the services whose name includes “emacs”. The output I have
right now is
PID
Exit Code
Server ID
1757
0
emacs_org
56696
0
emacs_work
It shows both Emacs servers are running fine with exit code 0.
Launch Emacs GUI in Terminal
I can now open a Emacs GUI and connect it to the “work” Emacs server
by running emacsclient -c -s work &. The -c option
Launch Emacs GUI in Spotlight
In MacOS, I found it is natural to open applications using Spotlight,
for example, type ⌘ + space to invoke Spotlight, put “work” in the
search bar, it narrows the search down to “emacs_work” application,
and hit return to finalise the search. It achieves the same thing as
the command above but can be used anywhere.
I uploaded a demo video on YouTube to show it in action. You might want
to watch it at 0.5x speed because I typed so fast…
To implement this shortcut, open “Automator” application, start a new
“Application”, select “Run Shell Script”, and paste the following bash
code
/opt/homebrew/opt/emacs-plus@31/bin/emacsclient \--no-wait\--quiet\--suppress-output\--create-frame-s work \"$@"
and save it as emacsclient_work in the ~/Application
folder.
Essentially, the bash script above is wrapped up as a MacOS
application, named emacsclient_work and the Spotlight searches the
application folder by default.
I’m working on replicating the (Re-)Imag(in)ing Price Trends paper -
the idea is to train a Convolutional Neutral Network (CNN) "trader" to
predict the stocks' return. What makes this paper interesting is the
model uses images of the pricing data, not in the traditional
time-series format. It takes financial charts like the one below
and tries to mimic the traders' behaviours to buy and sell stocks to
optimise future returns.
Alphabet 5-days Bar Chart Shows OHLC Price and Volume Data
To train the model, the price and volume data are transformed into
black-white images which is just a 2D matrix with 0s and 1s. For just
around 100 stocks' pricing history, there are around 1.2 million
images in total.
I used the on-the-fly imaging process during training: in each batch,
it loads pricing data for a given stock, sample one day in the
history, slice a chunk of pricing data, and then convert it to an image. It
takes about 0.2 milliseconds (ms) to do all that, so in total it takes 4
minutes to loop through all the 1.2 million images.
1.92 ms ± 26.9 µs per loop (mean ± std. dev. of 7 runs, 1,000 loops each)
To train 10 epochs, that's 40 minutes in loading data. To train one
epoch on the full dataset with 5,000 stocks, that's 200 minutes in
loading data alone!
PyToch utilises multiple processing in loading the data using CPU
while training using GPU. So the problem is less severe, but I'm using
the needle, the deep learning framework we developed during the
course, it does have this functionality yet.
During training using needle, the GPU utilisation is only around
50%. After all the components in the end-to-end are almost completed,
it is time to train with more data, go deeper (larger/more complicated
morel), try hyper-parameters tuning etc.
But before moving to the next stage, I need to improve the IO.
Scipy Sparse Matrix
In the image above, there are a lot of black pixels or zeros in the data
matrix. In general only 5%-10% of pixels are white in this dataset.
So my first attempt was to use scipy's spare matrix instead of numpy's
dense matrix: I save the sparse matrix, loaded it, and then convert it
back to a dense matrix for training CNN model.
967 µs ± 4.99 µs per loop (mean ± std. dev. of 7 runs, 1,000 loops each)
It reduces the IO time to 1ms, so about half of the time, not bad,
but I was expecting a lot more as the sparseness is high.
Numpy Bites
Then I realised the data behind images is just 0 and 1, in fact, a lot
of zeros, and only some are 1. So I can ignore the 0s and only need to
save those 1s, then reconstruct the images using those 1.
It is so simple that numpy has functions for this type of data
processing already. The numpy.packbites function converts the image
matrix of 0 and 1 into a 1D array whose values indicate where the 1s
are. Then the numpy.unpackbits does the inverse: it reconstructs the
image matrix by using the 1D location array.
This process reduces the time of loading one image to 0.2
milliseconds, that's 10 times faster than the on-the-fly method with
only a few lines of code.
194 µs ± 3.95 µs per loop (mean ± std. dev. of 7 runs, 10,000 loops each)
Another benefit is the file size is much smaller: it is 188 bytes
compared to 1104 bytes using sparse matrix. So it takes only 226MB of
disk space to save 1.2 million images!
It takes a couple of minutes to generate 1.2 million files on my Debian
machine. It is so quick! But then I release this approach is not
scalable without modification because there's a limited number of
files the OS can accommodate. The technical term is Inode. According
to this StackExchange question, once the filesystem is created, one
cannot increase the limit (Yes, I was there).
Without going down to the database route, one quick workaround is to
bundle the images together, for example, 256 images in one file. So
later in training, load 256 images in one go, then split them into
chunks. Just ensure the number of images is a multiple of the batch
size used in training so I don't have to deal with unequal batch
sizes. Since those bundled images are trained together, it reduces the
randomness of SGD, so I won't bundle too many images together, 256
sounds about right.
The LSP and other tools can cause problems when they are monitoring
folders with a large number of files. Moving them out of the project
folder is the way to go so Emacs won't complain or freeze.
I have been working on the Deep Learning System course. It is the
hardest course I ever studied after university. I would never thought
that I need CI for a personal study project. It just shows how
complex this course is.
Here is the setup: the goal is to develop a pytorch-like DL library
that supports ndarray ops, autograd, and to implement DL models, LSTM
for example, from scratch. That's the exciting math part. The tricky
part is it supports both CPU devices with C++11 and GPU devices with
Cuda. On the user front, the interface is written in Python. I worked
on my M1 laptop most of the time, and switch to my Debian desktop for
Cuda implementation.
It was a fine Saturday afternoon, I made a breakthrough in implementing
the gradient of Convolution Ops in Python after couple of hours of
tinkering in a local coffee shop. I rushed home, boosted up Debian
to test the Cuda backend, only to find "illegible memory access"
error!
It took me a few cycles of rolling back to the previous change in git to
find where the problems are. It made me think about the needs of
CI. In the ideal scenario, I would have a CI that automatically runs
the tests on the CPU and Cuda devices to ensure one bug-fix on CPU
side doesn't introduce new bugs on the Cuda, and vice versa. But I
don't have this setup at home.
Two Components of PoorMan CI
So I implemented what I call PoorMan CI. It is a semi-automated
process that gives me some benefits of the full CI. I tried hard to
refrain from doing anything fancy because I don't have
time. The final homework is due in a few days. The outcome is simple yet
powerful.
The PoorMan CI consists of two parts:
a bunch of bash functions that I can call to run the tests, capture
the outputs, save them in a file, and version control it
For example, wrap the below snippet in a single function
pytest -l-v-k"not training and cuda"\> test_results/2022_12_11_12_48_44__fce5edb__fast_and_cuda.log
git add test_results/2022_12_11_12_48_44__fce5edb__fast_and_cuda.log
a log file where I keep track of the code changes, and if the new
change fixes anything, or breaks anything.
In the example below, I have a bullet point for each change committed
to git with a short summary, and a link to the test results. The
fce5edb and f43d7ab are the git commit hash values.
- fix grid setup, from (M, N) to (P, M)!
[[file:test_results/2022_12_11_12_48_44__fce5edb__fast_and_cuda.log]]
- ensure all data/parameters are in the right device. cpu and cuda, all pass! milestone.
[[file:test_results/2022_12_11_13_51_22__f43d7ab__fast_and_cuda.log]]
As you can see, it is very simple!
Benefits
It changed my development cycle a bit: each time before I can claim
something is done or fixed, I run this process which takes about 2
mins for two fast runs. I would use this time to reflect on what I've
done so far, write down a short summary about what's got fixed and
what's broken, check in the test results to git, update the test log
file etc.
It sounds tedious, but I found myself enjoying doing it, it
gives me confidence and reassurance about the progress I'm making. The
time in reflecting also gives my brain a break and provides clarity on
where to go next.
During my few hours of using it, it amazes me how easy it is to
introduce new issues while fixing existing ones.
Implement in Org-mode
I don't have to use Org-mode for this, but I don't want to leave Emacs
:) Plus, Org-mode shines in literate programming where code and
documentation are put together.
This is actually how I implemented it in the first place. This section
is dedicated to showing how to do it in Org-mode. I'm sure I will come
back to this shortly, so it serves as documentation for myself.
Here is what I did: I have a file called poorman_ci.org, a full
example can be found at this gist. An extract is demonstrated below.
I group all the tests logistically together into "fast and cpu", "fast
and cuda", "slow and cuda", "slow and cuda". I have a top level header
named group tests, Each group has their 2nd-level header.
The top header has a property drawer where I specify the shell session
within which the tests are run so that
* grouped tests
:PROPERTIES:
:CREATED: [2022-12-10 Sat 11:32]
:header-args:sh: :session *hw4_test_runner* :async :results output :eval no
:END:
it is persistent. I can switch to the shell buffer named
hw4_test_runner and do something if needed
it runs asynchronically on the background
All the shell code block under the grouped tests inherits those
attributes.
The first code block defines variables that used to create a run
id. It uses the timestamp and the git commit hash value. The run id is
used for all the code blocks.
#+begin_src sh :eval nowd="./test_results/"ts=$(date +"%Y_%m_%d_%H_%M_%S")git_hash=$(git rev-parse --verify--short HEAD)echo"run id: "${ts}__${git_hash}$#+end_src
To run the code block, move the cursor inside the code block, and hit C-c
C-c (control c control c).
Then I define the first code block to run all the tests on CPU except
language model training. I name this batch of tests "fast and cpu".
#+begin_src sh :var fname="fast_and_cpu.log"fname_full=${wd}/${ts}__${git_hash}__${fname}
pytest -l-v-k"not language_training and cpu"\
2>&1 | tee${fname_full}#+end_src
It creates the full path of the test results. The fname variable
is set at the code clock header, this is a nice feature of
Org-mode.
pytest provides an intuitive interface for filtering tests, here
I use "not language_training and cpu".
The tee program is used to show the outputs and errors and at the
same time save them to a file.
Similarly, I define code blocks for "fast and cuda", "slow and cpu",
"slow and cuda".
So at the end of the development cycle, I open the poorman_ci.org
file, run the code blocks sequentially, and manually update the change
log. That's all.