Continuing from my last post, the EPA provides a seamless interface when
working with GPG files in Emacs. But there are situations where I have
to work with GPG files using other programs (mostly Python) which EPA
cannot help.
For those cases, I have to decrypt the GPG files first before using
them (for example, calling pandas.read_csv).
Obviously, there’s no point in encrypting a file if there is a
decrypted version next to it. So I also need a function to delete all
the decrypted files.
Emacs Lisp Implementation
Of course, I run Python inside of Emacs, I wrote the Lisp functions to
decrypt GPG files and delete all the decrypted files.
(defunyt/gpg--decrypt-recursively(root-dir)"It decrypts all the files ends .gpg under the root-dir. The decrypted files have the same filename but without the .gpg extension.
It stops if the decryption fails.
"(interactive)(dolist(file(directory-files-recursivelyroot-dir"\\.gpg"));; the 2nd argument for epa-decrypt-file can only be the base filename without the directory.(let((default-directory(file-name-directoryfile)))(epa-decrypt-filefile(file-name-basefile)))))(defunyt/gpg--delete-decrypted-files(root-dir)"It deletes the decrypted files under the root-dir directory.
e.g. if there's a file foo.tar.gz.gpg, it attempts to remove the foo.tar.gz file.
"(interactive)(dolist(file(directory-files-recursivelyroot-dir"\\.gpg"))(delete-file(file-name-sans-extensionfile))))
A bit of explanation:
directory-files-recursively: searches for files with a
pattern. Here, it returns all the files ending with .gpg under the
given root-dir,
dolist: loops over the GPG files to process them one by one,
epa-decrypt-file: decrypts a GPG file into a new file.
delete-file: deletes a given filename.
It seems the epa-decrypt-file function does not like the new
filename with the directory in its path, so I have to set the default
directory (working directory) and use the base filename after removing
the directory as a workaround.
Bash Implementation
It would be useful to have those functionalities outside of the Emacs,
so I implemented their counterpart in Bash.
function decrypt_recursively(){# PS: this function is equivalent to `gpg --decrypt-files $1/**/*.gpg`for fn in$(find $1-iname"*.gpg")do
echo decrypt ${fn} to "${fn%.*}"
gpg -o"${fn%.*}"-d"${fn}"done}function remove_decrypted_files(){for fn in$(find $1-iname"*.gpg")do
echo removing "${fn%.*}"rm"${fn%.*}"done}
The interface is the same: given a root directory, it decrypts all the
GPG files or deletes the decrypted files.
A little bit of Bash:
$1: refers to the first function argument, $2 refers to the
second function argument and so on. This is the Bash way. When the
function is called, $1 will be replaced with the actual argument,
here it means the root directory.
$(find …): is a list of files returned by the find program. In
this context, it stands for all the files whose filename ends with
.gpg.
It can be achieved using ls program but it will be a lot
slower 1 and requires some configuration in MacOS 2.
${fn%.*}: removes the last file extension of the variable $fn$,
for example, foo.tar.gz.gpg becomes foo.tar.gz.
Another approach is using $(basename $fn .gpg) to remove the
.gpg extension explicitly.
for, do, done: loops through each file.
The Bash functions have the advantage of being easily incorporated
into the system, for example, call the remove_decrypted_files
function automatically prior to shutting down or after login.
I have growing concerns about data security. It is not that I have
something to hide, it’s that I don’t like how my data is being
harvested in general by the big corporations for their own benefits,
which is mostly trying to sell me stuff that I don’t need or I
purchased already. Seeing the advertisements specifically targeting me
motivates me to do something.
Setting my personal cloud seems a bit too extreme, and I don’t have
the time for it anyway. So I did a little “off-the-grid” experiment
in which I exclusively used an offline Debian laptop for data
sensitivity work (password management, personal finance, diary
etc). It is absolutely secure for sure, but the problem is
accessibility: I can only work when I have access to the physical
hardware.
It becomes infeasible when I travel, and it gives me some headaches to
maintain one more system. Also, the laptop’s screen is only 720p, I
can literally see the pixels when I write; it feels criminal to not
use the MBP’s Retina display. Lastly, It cannot be off the grid
completely; at one point, I have to back it up to the cloud.
So I spent some time researching and learning. I just need a data
protection layer so that I don’t have to worry about leaking private
data accidentally by myself, or the cloud storage provider getting hacked.
The benefits include not only having peace of mind but also
encouraging myself to work on those types of projects with greater
convenience.
GNU Privacy Guard (GPG)
is the tool I settled with. It is a 24 years old software that enables
encrypting/decrypting files, emails or online communication in
general. It is part of the GNU project which weighs a lot to me.
There are two methods in GPG:
Symmetric method: The same password is used to both encrypt and decrypt
the file, thus the symmetric in its name.
Asymmetric method: It requires a public key to encrypt, and a
separate private key to decrypt.
There seems no clear winner in which method is better1. I choose
the asymmetric method simply for its ease of use. The symmetric method
requires typing the passwords twice whenever I save/encrypt the file
which seems too much.
The GPG command line interface is simple. Take the below snippet as an
example,
The first line encrypts the foo.org file using the public key identified as
“Bob”. It results in a file named foo.org.gpg.
The second line decrypts the foo.org.gpg file to foo2.org which will
be identical to foo.gpg.
EPA - Emacs Interface to GPG
Emacs provides a better interface to GPG: Its EPA package enables me
to encrypt/decrypt files in place. So I don’t have to keep jumping
between the decrypted file (foo.org) and the encrypted file
(foo.org.gpg) while working on it.
Below is the simple configuration that works well for me and its
explanation.
epa-file-enable: is called to add hooks to find-file so that
decrypting starts after opening a file in Emacs. It also ensures the
encrypting starts when saving a GPG file I believe.
To stop this behaviour, call (epa-file-disbale) function.
epa-file-encrypt-to: to choose the default key for
encryption.
This variable can be file specific, for example, to use the key
belonging to foo2@bar.com key, drop the following in the file
;; -*- epa-file-encrypt-to: ("foo2@bar.com") -*-
epg-pinentry-mode: should be set to loopback so that GPG reads
the password from Emacs’ minibuffer, otherwise, an external program
(pinentry if installed) is used.
Org-Agenda and Dired
That’s more benefits Emacs offers in working with GPG files. Once I
have the EPA configured, the org-agenda command works pretty well
with encrypted files with no extra effort.
In the simplified example below, I have two GPG files as
org-agenda-files. When the org-agenda is called, Emacs first try
to decrypt the foo.org.gpg file. It requires me to type the password
in a minibuffer.
The password will be cached by the GPG Agent and will be used to
decrypt the bar.org.gpg assuming the same key is used for both files. So I
only need to type the passphrase once.
After that, org-agenda works as if these GPG files are normal
unencrypted files; I can extract TODO lists, view the clock summary
report, search text and check schedules/deadlines etc.
The dired provides functions to encrypt (shortcut “:e”) and decrypt
(shortcut “:d”) multiple marked files in a dired buffer. Under the
hood, they call the epa-encrypt-file and epa-decrypt-file
functions.
Lisp to Close all GPG Files
It seems that once a buffer is decrypted upon opening or encrypted upon
saving in Emacs, it stays as decrypted forever. So I need a utility
function to close all the GPG buffers in Emacs to avoid leakage.
(defunyt/gpg--kill-gpg-buffers()"It attempts to close all the file visiting buffers whose filename ends with .gpg.
It will ask for confirmation if the buffer is modified but unsaved."(kill-matching-buffers"\\.gpg$"nilt))
Before I share my screens or start working in a coffee shop, I would
call this function to ensure I close all buffers with sensitive data.
My notes show I have had this issue since 9 months ago. I made another
attempt, but still could not find a solution!
Solution
I then switched to tidy up my Emacs configuration, and the variable
org-html-prefer-user-labels caught my eye.
its documentation says
By default, Org generates its own internal ID values during HTML
export.
When non-nil use user-defined names and ID over internal ones.
So “#org0238b9f” is generated by org-mode. They are randomly
generated; they change if I update the export file. It means every
time I update a blog post, it breaks the URLs. This was a problem I
wasn’t aware of.
Anyway, what’s important is that, in the end, it says
Independently of this variable, however, CUSTOM_ID are always
used as a reference.
That’s it, I just need to set CUSTOM_ID. That’s the solution to my
problem. It is hidden in the documentation of some variables…
Implementation
So I need a function to loop through each node, and set the CUSTOM_ID
property to its headline. The org-mode API provides three helpful
functions for working with org files:
org-entry-get: to get a textual property of a node. the headline
title is referenced as “ITEM”,
org-entry-put: to set a property of a node,
org-map-entries: to apply a function to each node.
I changed the final function a bit so it is used as an export hook
(org-export-before-processing-functions) as an experiment. With this
setup, it runs automatically whenever I export a blog post in org-mode
to Markdown. Also, it works on the exported file so it leaves the
original org file unchanged.
The code is listed below. It can also be found at my .emacs.d git repo
which includes many other useful Emacs configurations for Jekyll.
(defunyt/jekyll--create-or-update-custom_id-field()"so that the CUSTOM_ID property is the same as the headline and
the URL reflects the headline.
by default, the URL to a section will be a random number."(org-entry-putnil"CUSTOM_ID"(org-entry-getnil"ITEM")))(defunyt/jekyll--create-or-update-custom_id-field-buffer(backend)(when(eqbackend'jekyll-md)(org-map-entries'yt/jekyll--create-or-update-custom_id-field)))(add-hook'org-export-before-processing-functions'yt/jekyll--create-or-update-custom_id-field-buffer)
I’m the type of writer who writes first and comes up with the title
later. The title in the end is usually rather different to what I
started with. To change the title is straightforward - update the
title and date fields in the front matter.
However, doing so leads to discrepancies between the title and date
fields in front matter and the filename. In Jekyll, the filename
consists of the original date and title when the post is first
created.
This can be confusing sometimes in finding the file when I want to
update a post. I have to rely on grep/ack to find the right files. A
little bit of inefficiency is fine.
Recently, I realised that readers sometimes can be confused as well
because the URL apparently also depends on the filename.
For example, I have my previous post in a file named
2022-12-08-trx-3970x.md. It indicates that I started writing it on 08
Dec with the initial title “trx 3970x”. A couple of days later on 13
Dec, I published the post with the title “How Much Does Threadripper
3970x Help in Training LightGBM Models?”.
The URL is however yitang.uk/2022/12/13/trx-3970x. It has the correct
updated publish date, but the title is still the old one. This is just
how Jekyll works.
From that point, I decided to write a bit of Emacs Lisp code to help the
readers.
Emacs Lisp Time
The core functionality is updating the filename and front matter to
have the same publish date and title. It can breakdown into three
parts:
when called, it promotes a new title. The publish date is fixed to
whenever the function is called.
It renames the current blog post file with the new date and title.
It also updates the title and date fields in the front matter
accordingly.
It deletes the old file, closes the related buffer, and opens the
new file so I can continue to work on it.
My Emacs Lisp coding skill is rusty but I managed to get it working in
less than 2 hours. I won’t say it looks beautiful, but it does the
job!
I spent a bit of time debugging, it turns out the (org-show-all)
needs to be called first to flatten the org file, otherwise, editing
with some parts of the content hidden can lead to unexpected results.
I always found working with the filename/directory in vanilla Emacs
Lisp cumbersome, I wonder if is there any modern lisp library with a
better API, something like Python’s pathlib module?
Code
Here are the main functions in case someone needs something similar.
They are extracted from my Emacs configuration.
(defunyt/jekyll-update-post-name()"it update the post filename with a new title and today's date.
it also update the font matter."(interactive)(let*((title(read-string"new title: "))(ext(file-name-extension(buffer-file-name)));; as of now, the ext is always .org.;; the new filename is in the format of {date}-{new-title}.org(filename(concat(format-time-string"%Y-%m-%d-")(file-name-with-extension(jekyll-make-slugtitle)ext)));; normalise the filename. (filename(expand-file-namefilename));; keep the current point which we will go back to after editing.(old-point(point)))(rename-file(buffer-file-name)filename);; update the filename(kill-buffernil);; kill the current buffer, i.e. the old file.(find-filefilename);; open the new file.(set-window-point(selected-window)old-point);; set the cursor to where i was in the old file.;; udpate title field. ;; note jekyll-yaml-escape is called to ensure the title field is yaml friendly.(yt/jekyll-update-frontmatter--title(jekyll-yaml-escapetitle))))(defunyt/jekyll-update-frontmatter--title(title)"Update the title field in the front matter.
title case is used.
"(let*((old-point(point)));; ensure expand all the code/headers/drawers before editing.(org-show-all);; go to the first occurence of 'title:'.(goto-char(point-min))(search-forward"title: ");; update the title field with the new title.(beginning-of-line)(kill-line)(insert(format"title: %s"title));; ensure the title is in title case(xah-title-case-region-or-line(+(line-beginning-position)7)(line-end-position));; save and reset cursor back to where it started.(save-buffer)(goto-charold-point)))
Back in my Kaggle days, I always wondered how much my ranking could
improve with a better computer. I finally pulled the triggers (twice)
and got myself a 32-Cores Threadripper 3970x workstation.
Before I can tell if it helps my Kaggle competitions or not, I thought
it would be interesting to quantify how much benefits I can get from
upgrading the i5-13600k to 3970x in training LightGBM model.
The TLDR is:
The speedup is 3 times in training LightGBM using CPU.
To my surprise, it is 2 times faster using GTX 1080Ti GPU than
i5-13600k.
There are no obvious gains from GTX 1080Ti to RTX 3080.
Experiment Set up
I use the data in the Optiver - Trading At The Close
competition. There are about 500,000 rows and 100 features. I train a
3-fold (expanding window) LightGBM model. Repeating the same process
with varying numbers of cores used in the process to get a performance
graph like this:
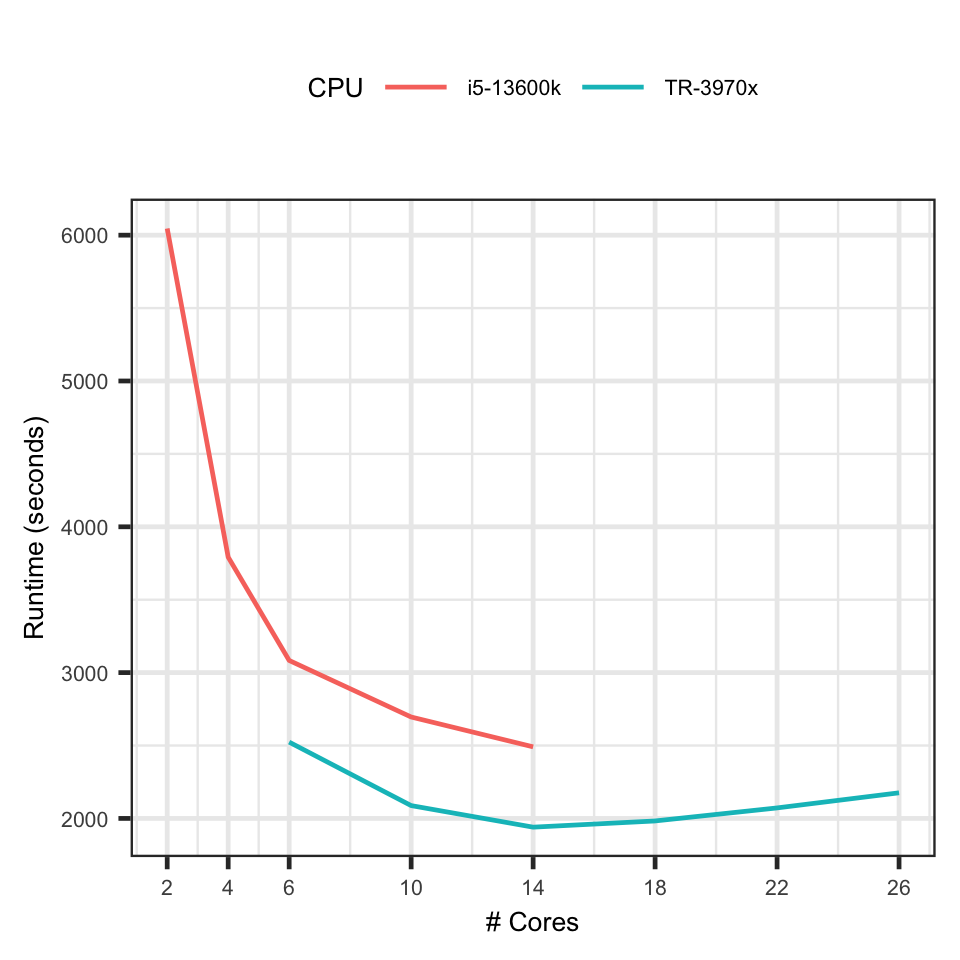
Threadripper 3970x vs i5-13600k: Train LightGBM Models on CPU
i5-13600k - Efficient Cores Count
The i5-13600k has 6 performance cores and 8 efficient cores. In
practice, I never use more than 6 cores in training ML models. My
theory is mixing fast performance and slow efficient cores leads to a
worse performance than using the performance cores alone. By
specifying 6 cores, I assume the OS uses only performance cores.
The result shows that I was wrong - Using more than 6 cores can give
considerable performance gain. It reduces the runtime by 10 minutes
from 6 to 14 cores.
The only plausible explanation is that when training LightGBM with 6
cores, it is already mixed with efficient cores. Therefore I see an
increases in performance while adding more cores.
Regardless I will start to use 12 cores in practise.
3970x - Disappointing Results
I know the performance gain will not scale linearly with the number of
cores but I wasn’t expecting that adding more cores can slow down the
model training.
The graph shows the 3970x achieves its best performance at using 12
cores. After that, adding more cores increases the runtime.
This type of behaviour is usually observed in simple tasks where the
overhead of coordinating between cores outweighs the benefits of extra
cores bring in.
But training thousands of decision trees with half a million data
points is definitive not in this simple task category. So I don’t
understand why this is happening.
i5 vs. 3970x - Training in Parallel
For 6 cores, it took i5 51 minutes and 3970x 42 minutes, which is about
1.2 speedup which is not bad. The same speed boost is also observed at
using 10 and 12 cores.
I found this consistent speedup confusing because there’s a mix of
performance and efficient cores in i5, so in theory every performance
core I add in 3970x should increase the performance marginal when
compared to i5.
In general, because of the poor scalability with respect to the number
of cores, the best performance is achieved when training the model with
a small number of cores and running multiple training in parallel. This is
the trick I use to get the extra performance boost for CPU-bound
tasks.
Here’s the setup for each computer:
i5-13600: use 6 cores to train each model, and train 2 models in
parallel. They are 2 cores left for OS background activities.
3970x: also use 6 cores to train each model, but train 5 models in
parallel! It also leaves 2 cores for OS background activities.
After a little bit of maths, it takes 14 hours for 3970x to train 100
models, and 42.8 hours for i5, so the speedup is 3 times. This is just
based on my theory. It would be good to actually run the experiment
and see the actual numbers.
Table 1: Training 100 models in parallel setting.
CPU
Runtime of 1 model (S)
No. models in Parallel
No. Batches
Total Runtime (H)
13600k
3083
2
50
42.8
3970x
2523
5
20
14.0
So the most benefit I can get from 3970x is in running multiple
experiments in parallel!
CPU vs. GPU - Impressive Performance
I have a GTX 1080Ti in my i5 PC for running deep learning models and
CUDA code. I never use it for LightGBM because the GPU implementation
was slower than the CPU in 2019 when I tried it.
In summer Guolin Ke, the author LightGBM, promised a significant
improvement in GPU performance when he was looking for volunteers to
work on improving LightGBM’s GPU algorithm.
Since I have the experiments set up already, it took me little time to
repeat the same experiments using the GPU trainer. All I did was adding
device_type=’gpu’ in the configuration files.
Table 2: Runtime of training a single mdoel
# CPU Cores
i5-13600k
tr-3970x
GTX 1080ti
RTX 3080
6
3083
2523
1435
1256
10
2695
1940
1269
1147
The result shocks me: I can get 2 times speedup just by switching from
i5 to 1080Ti with one additional line in the config and it outperforms
the 3970x in training single model setting by a big margin!
Is the 3970x worth it?
I found myself asking this question after seeing the results. In the
context of this experiment, no, it makes no sense to spend £2,000 to
get 3 times speedup when I can simply switch to 1080Ti to get 2 times
speed up with no costs.
However, the reason I go for the Threadripper and the TRX40 platform
is the 128 PCIe 4.0 lanes. The workstation is capable of running 4
GPUs at the same time at full capability while as i5 can only run 1
GPU.
If I had 4 GTX 3080 installed, it would finish training 100 models in
just under 8 hours! That’s 5.25 speedup to i5 and 1.75 speedup to
3970x in parallel setting.
This calculation is not for just entertainment. It turns out that
utilising multiple GPU to train gradient boost tree can be a really
big thing!